What is Fluentd
Fluentd 는 오픈소스 데이터 컬렉터로 잘 구조화된 로깅 레이어를 지원합니다.
from : What is Fluentd
Overview
Fluentd 를 가장 잘 나타내주는 그림 2장입니다.
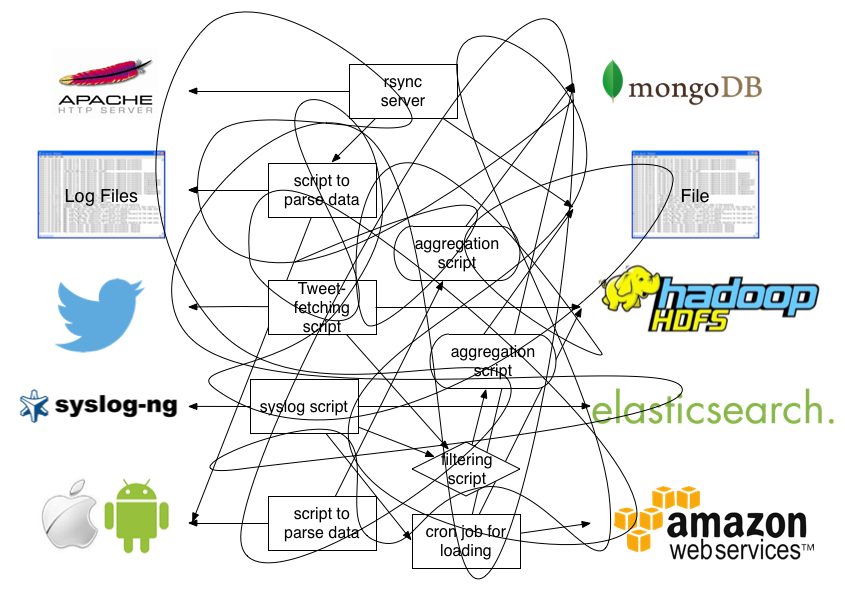
즉 위 그림을 보면 첫번재는 Fluentd 를 적용하기전 일반적인 로깅 경로입니다. 그야말로 스파게티죠, 호출하는 구조도 문제지만, 로그 형식도 각양각색입니다.
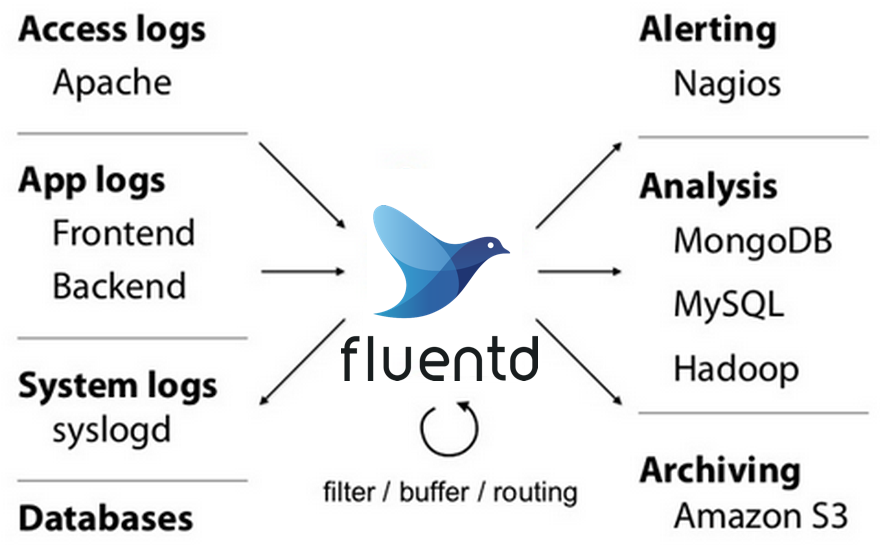
아래 그림은 Fluentd 를 적용 후 모습입니다. Fluentd Architecture 를 그려놓은 것입니다.
아파치로그, 앱(프런트/백)로그, 시스템, 데이터베이스 로그들이 Fluentd Agent 로 수집됩니다.
Fluentd Agent 는 필터링, 버퍼링, 라우팅을 통해서 적적한 로깅 시스템으로 로그 데이터를 전달합니다.
전달되는 로깅 시스템은 Nagios 알림, (MongoDB, MySQL, Hadoop) 데이터베이스 분석용, (Amazon S3) 아카이빙용 등다양합니다.
JSON 타입으로 로깅 지원

위 이미지를 보면 형식화된 JSON 으로 로깅을 수행합니다.
Fluentd 는 가능하면 JSON 형식의 구조화된 데이터로 변환을 시도합니다.
이는 로그 데이터 처리에 대해서 다양한 방법으로 수행이 된다.
- collecting
- filtering
- buffering
- outputting log across multiple source and destinations
플러그인으로 유연한 확장성
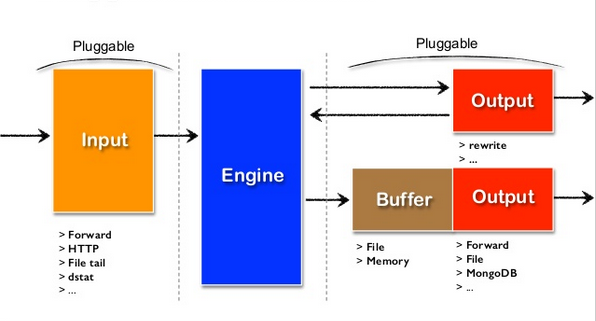
위 그림과 같이 Fluentd 는 다양하고 유연한 플러그인을 제공합니다.
많은 커뮤니티의 컨드리뷰터들이 이를 지원하고 있습니다.
요구사항 최소화
Fluentd 는 C 언어와 Ruby 조합으로 개발되었으며 매우 작은 리소스를 사용한다.
vanilla instance 는 30 ~ 40MB 정도 사용하며, 초당 13,000 건의 이벤트를 처리한다.
내장된 신뢰성
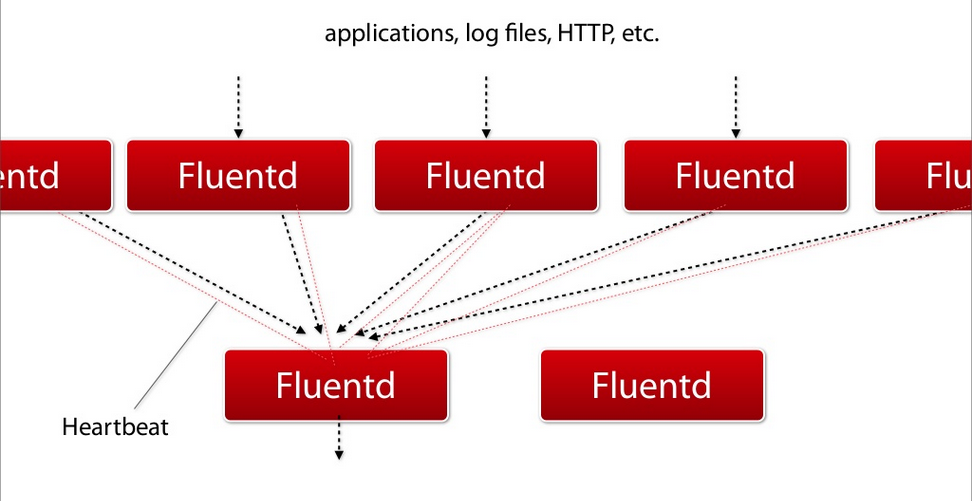
Fluentd 는 메모리 그리고 파일 기반의 버퍼링을 지원하여, 노드간 데이터 유실을 방지한다.
Fluentd 는 또한 강력한 failover 를 지원하고, 높은 가용성을 제공한다.
Unified Logging Layer: Turning Data into Action
from: Unified Logging Layer: Turning Data into Action
소개 : 액션을 위한 로그 데이터
과거 10년간 로그의 소비자는 사람이었습니다. 오늘날에는 사람에서 머신으로 이동했습니다.
몇몇 엔지니어는 시스템에 문제가 있을때 로그 확인을 위해 직접 로그를 확인하기도 합니다.
그러나 바이트로 처리된 로그 면에서 사람은 전체 소비의 매우 작은 일부부만을 수행 할 수 밖에 없습니다.
머신은 일별 로그 데이터를 밤낮으로 분석하고 리포트를 생산해 낼 수 있고, 통계적인 계산을 수행하여 의사결정을 할 수 있도록 해주고 있습니다.
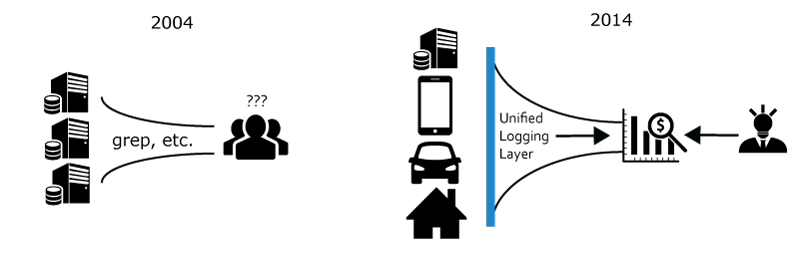
무어의 법칙과 분산된 시스템 디자인은 거대한 용량의 로그 처리가 필요하며, 데이터 마이닝을 접근하도록 만들었습니다.
그러나 여전히 많은 조직은 풍부한 금융과 인간의 자본이 동원되지만 자신들의 빠르게 증가하는 로그 데이터로부터 액션가능한 인사이트를 발견하는데 실패합니다.
이러한 이유는 Legacy 로깅 인프라 구조가 “machine-first” 로 디자인 되지 않았기 때문입니다. 그리고 다양한 벡엔드 시스템이 로그 데이터를 이해할 수 있도록 만들기 위해서는 많은 노력이 듭니다.
공통 인터페이스는 복잡도를 줄인다.
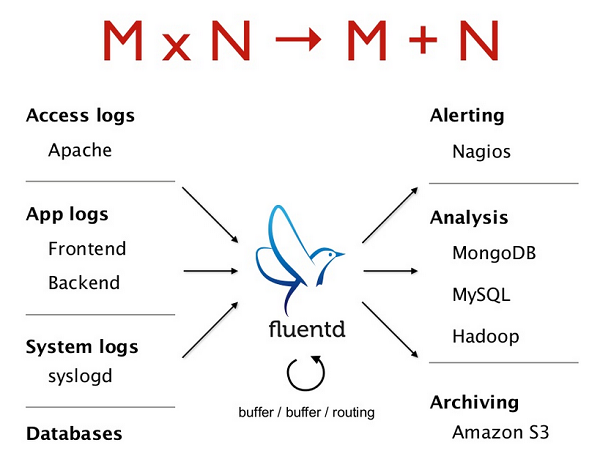
이미 존재하는 로그 포맷은 매우 구조적으로 취약합니다. 왜냐하면 인간은 텍스트를 번역하는 부분은 정말 잘합니다. 인간은 지금까지 로그 데이터의 첫번째 소비자였습니다.
마구잡이로 형식화된 텍스트는 로그 데이터 분석을 어렵게 만듭니다. 컴퓨터는 이러한 구조를 파싱하거나 정보를 뽑아내는데 매우 약하기 때문입니다. 이것이 왜 복잡한 정규식 표현이 인기가 있는지에 대한 이유이기도 합니다.
이러한 복잡도를 피하기 위해서 이론적으로 최소한 모든 로그 생성과 소비 사이에 인터페이스를 정의하는 것입니다. 이것이 Unified Logging Layer 를 구성하기 위한 첫번째 작업입니다.
엄격함 대 유연함
엄격함은 관리는 편하게 만들어주지만 확장성이 떨어진다. 그리고 로그를 개선하기 어렵게 만든다. 반면에 유연한 구조는 변경은 쉽게 해주지만 관리를 어렵게 합니다.
어디에든지 존재하게 하기
Unified Logging 레이어의 핵심 목표는 다양한 소스로부터 로그를 수집하여 다양한 목적지로 보내는 것입니다.
JSON 은 바이너리 프로토콜에 비해 느리다. 그러나 데이터베이스가 데이터를 처리할때 미들웨어는 이러한 커스텀 프로토콜을 지원하는지가 중요합니다.
JSON 은 이러한 부분에서 유연함을 제공한다. MongoDB 에 바로 저장되며, Hadoop 에 JSON SerDe 를 지원하고 있습니다.
중요 포인트는 Unify 로깅을 위해서 고려할 것은 미리 한가지 유즈케이스로 최적화를 하지 말라는 것입니다.
신뢰성과 확장성
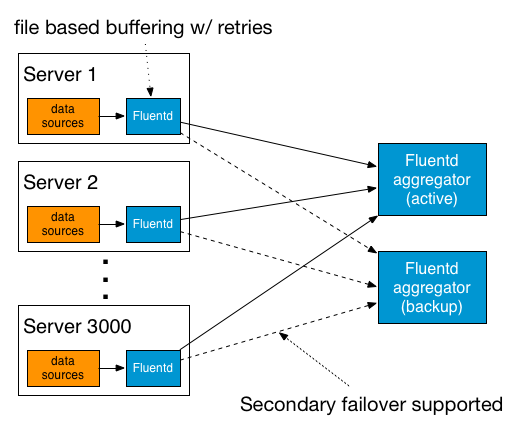
Unified Logging Layer 에서는 신뢰도와 확장성이 매우 중요한 부분입니다. 모든 로그 데이터는 Unified Logging Layer 를 통과한다. 이를 통해서 필터링, 버퍼링, 라우팅을 안전하게 수행할 수 있습니다.
수평 확장성이 필요하다.
로깅 레이어는 쉽게 수평 확장이 가능해야며, 큰 임팩트나 성능 저하 없이 수평확장이 가능해야합니다.
데이터 전송에서 리트라이가 필요하다.
Unified Logging Layer 는 네트워크 실패에 대한 고려를 해야하고, 데이터를 유실하지 않도록 해야합니다.
만약 Unified Logging Layer 가 푸시 기반의 시스템으로 구현되었다면 로깅 레이어는 데이터 재전송 기능을 지원해야합니다.
만약 logging 레이어가 풀 기반의 시스템으로 구현되었다면 로그 소비자는 성공적으로 데이터 전송에 대한 책임을 져야합니다.
- Push Based: 보낸는 쪽이 보장해야함
- Pull Based: 받는 쪽이 보장해야함.
최소화된 비용의 인프라 스트럭쳐 구성을 위한 확장 가능성
Unified Logging Layer 은 새로운 데이터 입력에 대한 준비를 해야한다. (새로운 서비스, 새로운 센서, 미들웨어등.) 그리고 출력은 (새로운 스토리지서버, 데이터베이스, API 엔드포인트) 등도 기술적 어려움 없이 지원해야합니다.
이러한 목표를 달성하기 위해서 Unified Logging Layer 는 플러그 가능한 아키텍처가 필요하다. 새로운 입력이 플러그 되어도 출력에 변화가 없어야합니다.
CS 백그라운드에서 플러그 가능한 아키텍처는 O(MN) 문제를 O(M+N) 으로 줄여줄여준다. M은 데이터 인풋, N 은 데이터 아웃풋이다. 여기에는 MN 가지의 패스를 가질 수 있습니다.
그러나 잘 플러그된 아키텍처는 오직 M+N 플러그인만 필요하게 합니다. 새로운 데이터가 입력되었을때 지원되는 코스트 혹은 출력은 O(1) 이 되도록 할 필요가 있습니다.
결론
지금까지 Fluentd 에서 제공하는 공식 사이트 문서, 그리고 공식 블로그를 통해서 Fluentd 가 무엇이고, 어떠한 철학을 가졌는지 알아봤습니다.
Fluentd 는 Unified Logging Layer 를 제공하여 입력된 데이터를 적절하게 필터링, 버퍼링하고, 최종적으로 출력하고자 하는 아웃풋 시스템으로 라우팅 하는 구조를 가진것을 알아봤습니다.
또한 어떻게 신뢰성 있는 시스템을 구성할 수 있는지도 알아 보았습니다.
마지막으로 Fluentd 가 확장이 되었을때 가이드라인도 함께 알아 보았습니다.